Master 2, Bases de données avancées, année 2022
Cours 2. Les key-value store
Dans le premier cours, nous avons vu que les garanties fortes apportée par les bases de données relationnelles avait des contreparties:
- difficulté de distribuer le calcul
- difficulté de faire évoluer le schéma
Dans la suite du cours, nous allons voir d’autres systèmes d’organisation des données offrant d’autre type de compromis que ceux offert par les bases de données relationnelles.
Les key-value store sont simplement des tableaux associatifs (où dictionnaires, où hash-table) avec le plus souvent (mais pas tous le temps, un fichier sur disque offrant une permanence aux données.
Il s’agit d’une des plus simple et plus vielle forme de stockage des données sur disque qui est massivement utilisé par l’applicatif pour avoir de la permanence des données à moindres coût et sans sur-couche logique compliquée.
Modèle de données
L’API d’un key-value store est très simple, on peut faire quelques opérations:
- Ajouter une clef et lui associer une valeur
- Récupérer la valeur associée à une clefs
- Lister toutes les clefs
Comme pour les bases de données, un key-value store non distribué peut facilement satisfaire les propriétés ACID. Ces dernières sont grandement simplifiée par la simplicité du modèle de données. Pour accélérés les performances, il y a souvent la possibilité d’introduire des des mécanismes de caches des propriétés ACID.
De part leur simplicité et leur performance, les key-value store peuvent être utilisé pour stocker des données simples en dehors du SI complexe, en embarqué dans de l’applicatif, ou même comme un cache pour les services web.
Un exemple simple: gdbm
gdbm (pour GNU dbm) est une librairie en C offrant une API pour manipuler des fichiers stockant des paires de clefs valeurs. De nombreux langages de programmation offre une interface respectant cette API et il existe même un petit programme en ligne de commande pour interagir avec ces fichiers simplement.
Il ne s’agit pas, à proprement parler, d’une base de données, il n’y pas de gestion des transactions, pas de mécanismes de client/serveur.
$ gdbmtool example.db store foo bar
$ gdbmtool example.db fetch foo
bar
$ gdbmtool example.db store foo barbar
$ gdbmtool example.db fetch foo
barbar
$ gdbmtool example.db store baz qux
$ gdbmtool example.db list
baz qux
foo barL’usage standard est dans l’applicatif ou les valeurs peuvent être n’importe quel suite de bytes, incluant donc des médias, des images, ou des textes compliqués.
Table de hachages
La plupart des stores de ce type s’appuient sur des tables de hachages pour retrouver les éléments associées à une clef.
Les points clefs à retenir:
- Une fonction de hachage va associer à chaque clef (quelque soit leur longueur) un indice dans un tableau de pointeur (par exemple vers le couple (clef, valeur)
- Il est possible que deux clefs soient associées au même indice, on dit alors qu’il y a une collision
- Si on insère deux clefs en collision, on utilise une des nombreuses stratégies de résolution des collision
Page Wikipédia à lire complètement. Pour les plus curieux, la page anglaise contient pas mal d’information supplémentaires.
Il existe de nombreuses variations autours de la résolution des collisions dans les tables de hachages. Le nombre de collisions dépend fortement du facteur de compression: \(\frac{n}{k}\) avec \(n\) le nombre de paires de clé-valeur et \(k\) le nombre d’alvéoles. Lorsque le taux de compression dépasse une certaine valeur (typiquement >50%) il faut agrandir la table pour éviter d’avoir trop de collisions.
Différents mécanismes permettent de faire ça, souvent en recopiant l’intégralité de la table, ce qui est une opération très couteuse (ré-hachage).
Dans les key-value stores, on s’interdit ce type d’opération trop couteuse, et on va choisir des fonctions de hashs dont le résultat ne dépend pas de la taille de la table. Cette propriété est très importante pour la distribution des tables de hachages, au point qu’on appelle ce problème the distributed hash table problem. On y reviendra plus tard.
Limitation des key-value stores
Contrairement aux base de données relationnelles, il n’est pas possible d’effectuer de recherches autre que par clef.
Un usage classique de ces stores consiste à sérialisé des données (par exemple en XML/JSON) et les désérialisées au besoin. On peut ainsi stocker des informations structurée simplement.
Supposons qu’on veut stocker des personnes dans la base de données:
import json
import dbm
cha = dict(name="Charles Paperman", job="Enseignant-Chercheur", mail="charles.paperman@univ-lille.fr", cours=["DBA", "AP2", "JS2"])
DBA = dict(titre="Database Avancée", enseignant="cha", parcours=["ML", "GL"])
db = dbm.open("departement_info")
db = dbm.open("departement_info", "c")
db["cha"] = json.dumps(cha)
db["DBA"] = json.dumps(DBA)La commande json.loads(db["cha"]) retourne alors l’objet
python
{'name': 'Charles Paperman',
'job': 'Enseignant-Chercheur',
'mail': 'charles.paperman@univ-lille.fr',
'cours': ['DBA', 'AP2', 'JS2']}Afin d’éviter le surcoût liés à sérialiser et désérialiser, certains stores comme Redis proposent de structurer les valeurs en offrant différent types de valeurs à manipuler. La manipulation de ces stores sera étudier en TD.
Une présentation rapide de Redis
Redis est une base de donnée key-value (et un peu plus, on va le voir).
Contrairement à gdbm il offre une architecture Client-Serveur et des mécanismes de distributions des données. Son modèle de données est aussi plus compliqué, les données pouvant avoir des types. Les données sont stockées et manipulées en mémoire vive avec des mécanismes de persistances pour ne pas perdre trop de données en cas de pannes.
Les usages classiques de Redis sont pour
l’intergiciel/middleware, pour implémenter des caches, ou des mécanismes
de passages de messages.
On peut évidemment s’en servir également comme d’une base de données clef-valeur classique, à condition que ça taille ne grossisse pas trop.
Modèle de données
Le modèle de données de Redis comporte plusieurs types de données et des jeux d’instructions dédiés à chaque type.
- Le type de bases sont simplement des chaines binaires et
sont manipulable via les commandes
GETetSET.
redis-cli SET MaClef 42Pour récupérer la valeur:
redis-cli GET MaClef- Le type list permet d’associer à une clef, une liste dynamique d’éléments.
redis-cli rpush une_liste "Un element"
redis-cli rpush une_liste "Un autre element"Pour récupérer tout (ou une partie) de la liste, on peut utiliser
redis-cli lrange une_liste 0 3Qui retourne
1) "Un element"
2) "Un autre element"- Le type hash permet de stocker un sous ensemble de clef valeur:
redis-cli hmset 42 nom "Charles Paperman" email "charles.paperman@univ-lille.fr" tel "06xxxxxxxx"On peut récupérer une valeur à la fois
redis-cli hget 42 nomRetourne Charles Paperman
Ou récupérer toutes les valeurs
redis-cli hgetall 42Retourne
1) "name"
2) "Charles"
3) "email"
4) "charles.paperman@univ-lille.fr"
5) "nom"
6) "Charles Paperman"
7) "tel"
8) "06xxxxxxxx"- Des types ensembles, ensembles ordonnées, des compteurs, et d’autres
Pour avoir plus de détails, ici
Redis et la durabilité
Redis est une base de données en mémoire, la totalité des données doivent tenir en RAM. Il est néanmoins possible de faire des sauvegardes a intervalle réguliers, ce qui permet une certaine persistance des données.
Redis propose différent niveau de durabilité:
- Aucune persistance sur disque
- Une persistance via un fichier binaire
- Une persistance via un ficher de log
- Les deux derniers points simultanée.
Redis et la disponibilité
Redis offre un mécanisme de réplication classique (avec Primary/Replicas). En cas de problème réseaux, la réplique se resynchronise et le système reste disponible.
Il s’agit d’un système qui est Disponible mais pas nécessairement cohérent.
La distribution de Redis
Redis a des mécanismes de distributions basez sur rendez-vous hashing (voir plus loin dans le cours). Ils ne garantissent pas la cohérences et il est possible de perdre des données de manière silencieuse en cas d’interruption réseau.
La distribution des key-value store
La simplicité du modèle de données, permet de distribuer les données plus simplement que dans le cas des SGBD. Dans ce contexte, on doit simplement distribuer la table de hachage entre plusieurs nœud (on parle de cluster ou grappe) et possiblement autoriser l’ajout de nœud quand le facteur de compression de la table dépasse un certain taux.
Pour distribuer la table de hachage, un client doit décider sur quelle machine stocker sa paire de (clé, valeur). Une stratégie naïve pour un cluster de taille \(n\), est simplement de numéroter chaque nœud de \(0\) à \(n-1\) une fois pour toute. Pour insérer une clé, il suffit alors de calculer le hash de la clé modulo n pour obtenir le nœud cible.
On peut éventuellement demander à un programme intermédiaire (middleware) de faire la passerelle et de choisir pour le client le nœud cible..
Les key-value store ont vocation à être utilisé comme des cache et donc vise la disponibilité au détriment de la cohérence (voir le Théorème CAP du premier cours). Il est donc nécessaire d’indiquer comment les mécanismes de distributions impactent les performances du système et comment les conflits sont résolus.
Efficacité de la distribution, coût de l’extensibilité
On peut mesurer l’efficacité d’une table de hachage distribuée dans plusieurs dimensions:
- Le coût de l’extensibilité (ajout/suppression de nœuds)
- Le coût de la réplication (le nombre de machine par rapport au facteur de réplication).
Pour simplifier l’analyse, on peut supposer que le réseau est toujours le goulot d’étranglement. On veut donc limiter la quantité d’échange entre les machines en fonctions de la variation du nombre de serveur (en ajout et suppression de serveur à la grappe).
Ainsi on mesure principalement ses opérations en temps de communication entre les serveurs. On parle alors de complexité de la communication.
Pour Redis il n’y pas de mécanisme de sharding
mais une architecture Primary/Replicas et des mécanismes de distribution
des données par valeur de hash.
Le goulot d’étranglement est souvent autours de l’élasticité de la grappe de serveur: lorsqu’on ajoute ou on retire un nœud, il faut alors transférer des données. La quantité de données transféré va dépendre des algorithmes de distribution utilisés.
Stratégie naïve
On pourrait tout à fait utiliser une stratégie naïve de recalculer à l’ajout/suppression d’un serveur la position de la totalité des clefs/valeurs de la table. Cela entraîne une complexité de la communication importante.
Pour l’estimer, on suppose que \(n\) clef-valeurs sont distribuées uniformément sur \(C\) cluster avec un taux de réplications de \(k\), alors ça donne \(n\) clefs à répartir sur \(C\) serveurs avec chaque clef qui doit être présente sur \(k\) serveurs. Si on ajoute un serveur alors on aurait \(n\) clefs à re-répartir sur \(C+1\) serveur uniformément avec un taux de réplication de \(k\).
Si \(k=1\), c’est le cas le plus simple à analysée. Chaque donnée à une probabilité \(\frac{C}{C+1}\) de devoir migrer. En moyenne on aura donc \(\frac{Cn}{C+1}\) migration de clef, ce qui tend vers \(1\) rapidement quand le nombre de serveur augmente.
Pour \(k>1\), chaque donnée est présence sur \(k\) serveur et donc la probabilité de devoir migrer \(0\leq t\leq k\) copies de la clé peut être estimé par la probabilité qu’un clef doivent être copié \(t\) fois sur des nouveaux serveurs. Pour ça, il faut qu’elle soit présente après la migration sur exactement \(k-t\) serveur où elle était déjà présente. Pour un ensemble de \(k-t\) serveurs, la probabilité de les choisir eux et exactement eux peut s’écrire: \[\frac{1}{C+1\choose k-t} \cdot \Pi_{i=0}^t\frac{C -k -i}{C+1}\]
Comme il y a \({k \choose k -t}={k\choose t}\) possibilité, cela donne que la probabilité d’avoir exactement \(t\) copies de la clef est:
\[C_t := \frac{{k \choose t}}{C+1\choose k-t} \cdot \Pi_{i=0}^t\frac{C -k -i}{C+1}\]
Finalement, le taux de migration est \(\sum_{t=0}^k tC_t\). Il s’agit du nombre de copie de la base de données (sans duplicat) qui doit être transféré entre les instances pour ajouter un serveur supplémentaire.
On peut tracer le taux de migration en fonction de \(C\) pour un facteur de réplication fixé à 3:
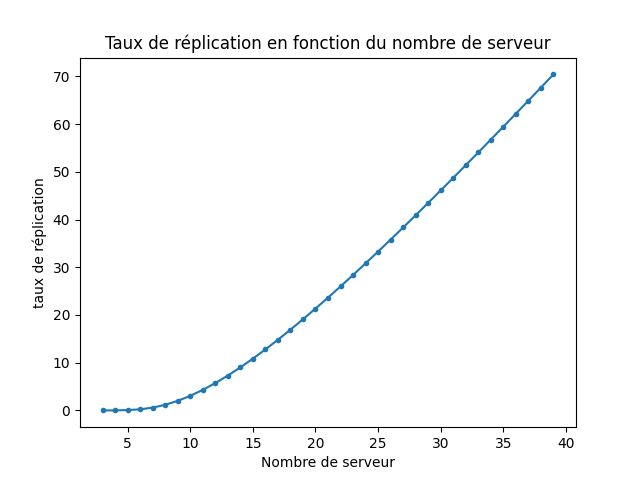
On voit que dans l’approche naïve, le coût de l’élasticité devient rapidement important, avec l’ajout d’un serveur qui nécessite de transférer plusieurs fois le contenu de la base entre les différents serveur.
Rendez-vous hashing
Pour un cluster avec \(n\) nœuds, on associe à chaque nœud un ensemble d’identifiant au hasard \(i_1, \ldots,i_n\).
Pour ajouter une clé \(u\) au cluster, calcul avec une fonction de hash \(h\), des poids \(w_1 = h(i_1, u), w_2=h(i_2, u), \ldots, w_n=h(i_n, u)\). Le client choisit le nœud \(i_t\) dont le poids est maximal, c’est-à-dire, tel que \(w_t\geq w_i\) pour tout \(i\).
- Si on retire un nœud, on redistribue ses clefs en les réinsérant
- Si on ajoute un nœud, on doit déterminer sur l’ensemble des clés du cluster, celles qui doivent migrer.
La dernière étape nécessite le re-calcul pour toutes les clés du cluster de leur poids par rapport au nouveau serveur. Ce qui est couteux mais ne nécessite pas de transfert réseau.
Consistent hashing
Pour un cluster avec \(n\) nœuds, on assigne à chaque nœud \(k\) positions sur le cercle unité au hasard uniformément. On suppose qu’on a une fonction de hash uniforme sur le cercle unité pour les clés.
Étant donnée une clé, on calcul sa position sur le cercle unité et on détermine le nœud ayant une position sur le cercle le plus proche et on lui assigne la clé.
- Si on souhaite retirer un nœud du cluster, on distribue ses clés-valeurs en les réinsérant.
- Si on souhaite ajouter un nœud au cluster, on calcul ses positions et on calcul pour chaque clefs dans les nœuds adjacents
Pour chaque ajout de nœud, on aura au pire \(k\) nœuds à modifier. On laisse donc inchangé \(k(n-1)\) nœud et une grosse fraction de la base de données.
notes faites en cours à distance
Compiled the: ven. 05 sept. 2025 16:27:44 CEST