Master 2, Bases de données avancées, année 2023
Cours 1. Les systèmes de gestion de base de données (SGBD)
Un système de gestion de base de données est un logiciel système servant à stocker, manipuler ou gérer, et à partager des données dans une base de données, en garantissant la qualité, la pérennité et la confidentialité des informations, tout en cachant la complexité des opérations.
(source: wikipedia)
Ce sont des logiciels au cœur des systèmes d’informations. Un utilisateur d’un tel logiciel peut être aussi bien un personnel sans compétences techniques au travers des logiciels et des formulaires qu’un développeur qui met en place et automatise certains processus.
Les SGBD peuvent être utilisés aussi bien pour analyser des données (on parle alors de base de données analytique ou OLAP) que pour modéliser l’état en temps réel d’un système, une organisation, une application (on parle alors plutôt de base de données transactionnelles).
Ce sont des logiciels qui simplifient grandement la gestion des données en fournissant à la fois une abstraction du système de fichiers avec un langage de requêtes souvent déclaratif et des capacités d’optimisation et de passage à l’échelle. Il ne faut pas confondre :
- le logiciel (exemple: PostgreSQL, Oracle, MySQL, ElasticSearch, MongoDB, etc…) ;
- le langage de requêtes (les variantes autours de SQL, SparQL, AQL, LDAP, etc…).
La variante de SQL utilisée par PostgreSQL est utilisée par d’autres SGBD comme DuckDB. Les services cloud proposent des bases de données automatiquement adaptées à leur infrastructure et souvent basées sur des SGBD open-source classiques. Par exemple Amazon RDS est basé sur MySQL, Amazon Redshift sur PostgreSQL. Le nouveau service AlloyDB de Google Cloud est basé sur PostgreSQL.
Un SGBD doit réaliser les taches suivantes :
- permettre la mise à jour incrémentale des données ;
- permettre de les interroger efficacement et simplement ;
- gérer les problèmes d’accès concurrents ;
- fournir des mécanismes pour garantir la durabilité des données.
Dans ce cours, nous allons supposer que les concepts de BDR sont connus et maîtrisés et étudier les bases de données dans leur écosystème. Nous allons faire un focus sur :
- la haute disponibilité et le théorème CAP ;
- les modèles de données non-relationnels ;
- le lien entre l’applicatif et les bases de données.
Vous avez vu en BDR l’acronyme ACID :
- Atomique
- Cohérent
- Isolé
- Durable
Ces propriétés sont importantes pour garantir que le système se comportera comme prévu. Néanmoins, certaines garanties sont trop coûteuses et uniquement partiellement satisfaites. Par exemple, l’isolation des transactions peut être ajustée afin d’éviter que trop de transactions ne soient rejetées.
Les bases de données sont tellement critiques pour les systèmes d’exploitation qu’elles embarquent des mécanismes de redondances afin d’éviter que leur mise en échec entraîne avec elles l’ensemble de l’infrastructure.
La gestion fine des transactions dans une base de données relationnelles est à la fois critique et très subtile. Vous pouvez lire sur ce sujet:
- La documentation de PostgreSQL qui est instructive
- Ce poste montre des limitations de l’implémentation de PostgreSQL et quelques points historiques
La haute disponibilité
Pour garantir une meilleur robustesse aux pannes, il existe des mécanismes pour palier aux pannes, certains intégrés dans le middleware, d’autres directement dans les SGBD. Le terme haute disponibilité fait référence à des mécanismes (parfois très complexes !) visant à garantir qu’une ou plusieurs pannes simultanées n’entraînent pas d’interruption de service.
Classiquement, une application va avoir un serveur qui héberge une base de données. Ce dernier peut tomber en panne ou être inaccessible, pour de nombreuses raisons : mise à jour logicielle ratée, le serveur est pris d’assaut par trop de connexions simultanées, une tractopelle a coupé une fibre optique, un datacenter est en flamme.
L’ensemble de l’infrastructure doit être hébergé de manière redondante pour permettre au service d’être résilient aux pannes et aux pertes de données. Pour une base de données, la solution naturelle consiste à avoir deux (ou plus !) bases de données qui sont synchronisées et dans le même état. Si chacune des bases de données accepte des requêtes en écriture, la gestion des conflits et des transactions devient très compliquée, une simplification classique consiste à avoir une unique base de données primaire en lecture et écriture et une ou plusieurs répliques en lecture seule. Cela permet également de répartir la charge en lecture sur le SGBD car les répliques peuvent également répondre à des requêtes.
Quand la base de données primaire tombe, une des secondaires peut basculer (on parle de failover) et devenir la base de données primaire.
PostgreSQL propose de nombreuses solutions différentes pour mettre en place de la haute disponibilité, avec avantages et inconvénients très variés. Voir la documentation
Il existe même des solutions avec plusieurs SGBD primaires et une résolution des conflits semi-manuelle.
Dans le cadre d’une base de données hautement disponible comment doivent se comporter les propriétés ACID :
- globalement : l’ensemble du système doit être ACID ;
- localement : chaque base de données est localement ACID mais le système global ne l’est pas
Lorsqu’on souhaite être globalement ACID, cela signifie que toutes les répliques doivent valider les modifications pour que celles-ci soit validées globalement. Cela peut ajouter beaucoup de latence au système mais cela garantit que toutes les requêtes en lectures envoyées à une réplique au hasard sont toutes cohérentes les unes aux autres. Le système peut devenir indisponible quand une des répliques ne répond pas suite à un problème réseau.
Si on ne maintient les propriétés ACID que localement, alors le système est plus réactif mais il peut y avoir des problèmes de cohérence quand une base de données répliquée n’est pas synchronisée avec une autre et mettre l’ensemble du système dans un état incohérent.
Une infrastructure complète disponible est compliquée. Le schéma
suivant peut la résumer : 
Un système / deux cerveaux (split brain).
Il est possible en cas de panne réseau que le système se retrouve partitionné en deux morceaux autonomes. Les mécanismes de failover peuvent promouvoir sur un des réseaux une nouvelle base de données primaire et on peut alors se retrouver avec deux systèmes autonomes et non-synchronisés l’un avec l’autre.
Si la solution perdure dans le temps, cela peut occasionner que les deux systèmes divergent et que le système soit dans un état durablement inconsistant.
Le Sharding
Les solutions primaires/repliques nécessitent d’avoir plusieurs copies de la base de données pour garantir la haute disponibilité et la répartition de la charge de travail. Cela signifie qu’ajouter des serveurs nécessite que chaque serveur soit dimensionné pour accueillir l’ensemble de la base de données.
Dans le cas d’applications qui gèrent de très gros volumes de données, cela peut être rédhibitoire. Il faut alors des mécanismes pour garantir la haute disponibilité et la répartition de la charge de travail, sans pour autant que chaque machine ne contienne l’ensemble des données.
On va décomposer l’ensemble des données en éclats (ou shard en anglais) et chaque éclat va être hébergé sur une ou plusieurs machines. Toutes les instances peuvent écrire ou lire des données et une instance est responsable d’une partie de la base. Quand une instance reçoit une requête en écriture ou en lecture pour un éclat, elle doit les envoyer aux machines qui sont censées s’en occuper. Il faut donc un mécanisme de décision pour, qu’étant donné un shard, on puisse savoir à quelle machine il appartient.
Il y a plusieurs stratégies :
- à base de fonctions de hash (on hash les clefs primaire et on les rassemble en fonction de la valeur de la clef) ;
- à base de valeurs sémantiques (on définit une partition des données basée sur une origine géographique).
Pour un système distribué donné, les paramètres importants sont :
- le taux de réplications : le nombre de copies de l’éclat disponible sur des machines différentes ;
- le nombre d’instances.
On peut avoir un taux de réplication de 1 sur 3 machines. Cela signifie que le système n’est pas hautement disponible : il suffit qu’une machine ne soit plus accessible pour que 1/3 des données ne soit plus disponible.
On peut avoir un taux de réplication de 2 sur 3 machines. Cela signifie que chaque éclat est sur deux machines. Le système garantit que l’ensemble des données reste accessible même si une des machines est indisponible.
On peut avoir un taux de réplication de 3 sur 3 machines. Il s’agit en fait d’un mécanisme de réplication total de la bases de données sur chaque serveur.
Le théorème CAP pour les systèmes distribués
Les explications et les illustrations viennent du poste de blog de Michael Whittaker.
On suppose qu’il est nécessaire de partitionner les données en plusieurs éclats présents sur plusieurs serveurs.
Les SGBD sont conçus pour apporter des garanties sur leur fonctionnement, y compris lorsque des pannes arrivent. Ainsi, les propriétés ACID permettent la garantie qu’un SGBDr qui donne une réponse de validation d’une requête l’a forcément prise en compte et a laissé le système dans un état valide. Si le système a une panne, alors il n’y aura de perte de données que dans les cas extrêmes (système sans mécanisme de répliques avec le disque dur détruit par exemple).
Les SGBD distribués doivent également prendre en compte la possibilité que des pannes arrivent. Au contraire des systèmes classiques, les pannes sont fréquentes (pas forcément des nœuds de calcul, mais de leur interconnexion).
Dans l’absolu, les garanties recherchées sont :
- la cohérence de la base ;
- la disponibilité de la base.
Nous allons voir que malheureusement, ces deux garanties ne peuvent être satisfaites simultanément pour un SGBD distribué.
Il s’agit du Théorème CAP.
Pour illustrer ce théorème, on va prendre un cas simple : deux nœuds \(G_1\) et \(G_2\) partagent une variable \(x\) qui a une valeur \(v_0\). On suppose que des clients peuvent se connecter pour écrire et lire cette variable pour chacun des deux nœuds.

Cohérence
On suppose qu’un client modifie la variable en envoyant une requête au nœud \(G_1\). Ce dernier accepte la modification et le signale au client. Pour que la base soit cohérente, il faut que si on requête la valeur \(x\) à \(G_1\) ou \(G_2\), cette valeur soit identique.
- Illustration d’un enchaînement incohérent
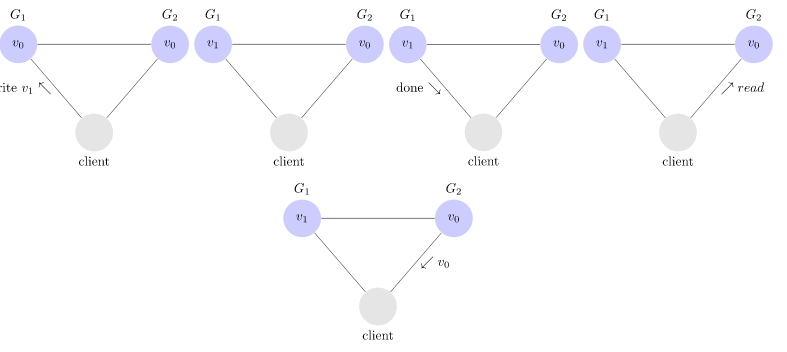
- Illustration d’un enchaînement cohérent:
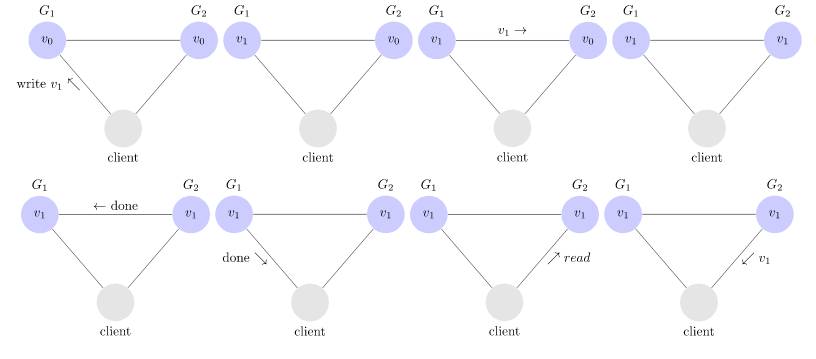
Pour que le système soit cohérent, il faut donc que \(G_1\) communique avec \(G_2\) pour mettre à jour la valeur sur tout le système avant de répondre au client que sa valeur a été acceptée.
Disponibilité
La disponibilité quant à elle est la contrainte que chaque requête doit recevoir une réponse.
La preuve du théorème
Si on suppose que la connexion entre \(G_1\) et \(G_2\) est interrompue et qu’un client souhaite mettre à jour la valeur. On a alors deux possibilités :
- soit le système est cohérent, il ne peut valider la mise à jour et n’est donc pas disponible ;
- soit le système valide la mise à jour et qu’une requête arrive sur \(G_2\), alors le système n’est pas cohérent.
Résumé du premier cours
- Les SGDBR sont les Systèmes de gestion de bases de données standards. Ils sont adaptés à de très nombreuses situations et performants.
- Leur efficacité en tant que système est formalisée au travers de leur respect (plus ou moins strict) des propriétés dites ACID.
- Quatre contreparties notables à cette efficacité :
- la difficulté de faire communiquer un SGBDR avec un langage orienté object (Object Relational Impendance mismatch) ;
- la difficulté de faire évoluer un schéma relationnel ;
- une interaction avec l’applicatif compliquée ;
- la difficulté de rendre le système extensible aux très fortes charges, notamment en écriture.
- La distribution c’est compliqué : Le Théorème CAP.
Remerciements
Aux correcteurs anonymes.
Compiled the: ven. 05 sept. 2025 16:27:54 CEST