Algorithmes et Programmation 2, année 2023
Mutable et non-mutables
Il faut distinguer en Python les variables et les valeurs. Une variable est un nom donné à une valeur. Cette valeur a un type qui est implicite dans le langage.
x = 3 # la variable x pointe vers la valeur entière (type int) 3
x = "coucou" # la variable x pointe vers la valeur *chaine de caractère* (type str) coucou
x = (3, "coucou") # la variable x pointe vers un couple (type tuple) de valeur.Les types en Python se décompose en deux groupes:
- les types représentant des éléments non-mutable
- les types représentant des éléments mutable
Pour simplifier, si un tuple est mutable alors on peut modifier son contenu sans créer une nouvelle valeur. Au contraire, s’il n’est pas possible de modifier une valeur, alors celle ci est non mutable.
Quelques exemples
Les chaines de caractères (en Python) sont non-mutables.
s = "ceci est une chaine"
s[3] = "a"Traceback (most recent call last):
File "/var/www/cha/check_py_md", line 81, in repl
exec(code, env)
File "<string>", line 2, in <module>
TypeError: 'str' object does not support item assignmentOn ne peut pas modifier une case de la chaine de caractère. Attention, Python peut être un peu subtil sur le sujet:
x = "" # ceci est une chaine de caractère
x += "a" # x prends une nouvelle valeur
x += "b" # x prends encore une autre valeurAu contraire, les listes sont mutable
L = list("ceci est une liste")
L[3] = "a"
print(L)['c', 'e', 'c', 'a', ' ', 'e', 's', 't', ' ', 'u', 'n', 'e', ' ', 'l', 'i', 's', 't', 'e']Dans ce dernier exemple, on a modifier la 3ème cellule de la liste.
La liste à donc changer mais la variable L pointe vers la
même valeur.
Le cas des tuples
Les tuples sont un peu compliqué: ils ne sont pas mutables en soit, comme le montre l’exemple suivant:
t = (1, 2, 3)
t[1] = 3Traceback (most recent call last):
File "/var/www/cha/check_py_md", line 81, in repl
exec(code, env)
File "<string>", line 2, in <module>
TypeError: 'tuple' object does not support item assignmentPar contre, ils peuvent contenir des objets mutables, ce qui leur donne un statut un peu particulier.
t = ([], [])
print(t, id(t))([], []) 139955346115072t[0].append(0)
print(t, id(t))([0], []) 139955346115072Sous le capot (un peu)
Pour comprendre cela, on peut utiliser une fonction qui associe à
chaque objet un entier qui représente son adresse dans la mémoire: id
s = "ceci est une chaine"
print(s, id(s))ceci est une chaine 139955348470112s += "!"
print(s, id(s))ceci est une chaine! 139955348470272On voit ici, que l’ajout de ! à modifier
l’id de la fonction. La deuxième chaine de caractère
représente un espace mémoire nouveau.
L = list("ceci est une liste")
print(L, id(L))['c', 'e', 'c', 'i', ' ', 'e', 's', 't', ' ', 'u', 'n', 'e', ' ', 'l', 'i', 's', 't', 'e'] 139955346114944L.append("!")
print(L, id(L))['c', 'e', 'c', 'i', ' ', 'e', 's', 't', ' ', 'u', 'n', 'e', ' ', 'l', 'i', 's', 't', 'e', '!'] 139955346114944Au contraire, ici l’id ne change pas car L
est le même objet après append.
Un récap
Les types primitifs sont souvent non-mutable:
- Les nombres (int, complex, float, etc.)
- Les chaines de caractères
- Les tuples d’éléments non-mutables sont non-mutables.
Les structures de données sont souvent mutables:
- Les listes
list - Les dictionnaires
- Les ensembles
- Les tuple dont un des éléments n’est pas mutables.
Les subtilité algorithmique
La (non-)mutabilité, entraine immédiatement plusieurs subtilité:
voici deux fonctions très très similaire:
def f(n):
t = tuple() # tuple vide
for i in range(n):
t += (" ",)
return tdef g(n):
L = list()
for i in range(n):
L.append(" ")
return Lprint(f(4))(' ', ' ', ' ', ' ')print(g(4))[' ', ' ', ' ', ' ']A priori, il n’y a aucune raison que ces deux fonctions aient une complexité différentes. Voici ce qu’il se passe quand on trace les courbes de temps constatés:
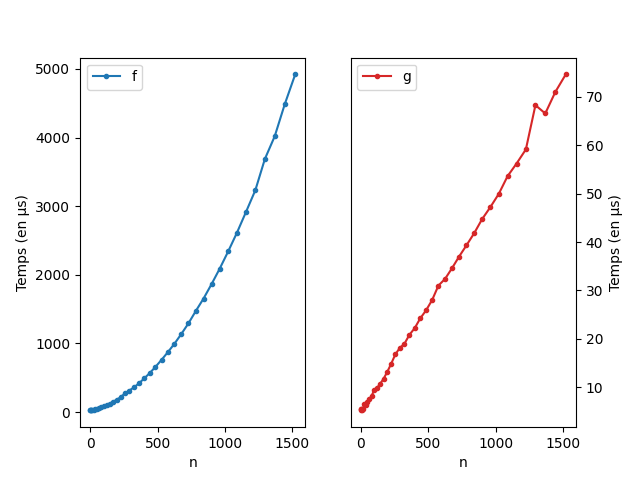
Clairement, la première version est de complexité quadratique alors
que la seconde est linéaire. Ici, l’ajout à une liste ne nécessite pas
une copie complète de la liste alors que l’ajout à un
tuple lui le nécessite. Donc chaque t += (," ") prends en
fait O(i) étape et donc la complexité total est quadratique.
Ce n’est pas le cas pour les chaînes de caractères qui sont optimisées intelligemment par Python.
Lorsqu’on fait s += " " avec s une chaîne,
Python s’arrange pour éviter la copie complète.
Les listes sont subtiles sur ce sujet. Certaines opérations vont entrainées des copies et d’autres non sans que cela soit explicite. Par exemple:
L = list()
print(L, id(L))[] 139955346118208L += [" "]
print(L, id(L)) # pas de copie!![' '] 139955346118208Par contre:
L = list()
print(L, id(L))[] 139955346119104L = L + [" "]
print(L, id(L)) # Une copie !!![' '] 139955346114944On peut d’ailleurs constater ça expérimentalement:
def g2(n):
L = list()
for i in range(n):
L += [" "]
return Ldef g3(n):
L = list()
for i in range(n):
L = L + [" "]
return LVoici les courbes:
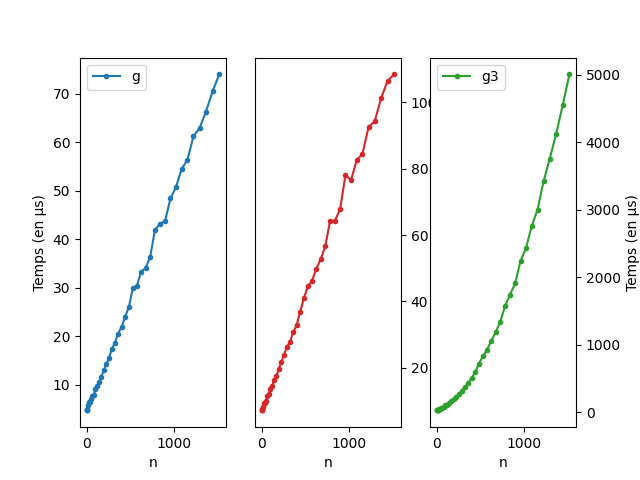
Une dernière subtilité provient des slices de listes.
Quand on prends une liste, la notation [i:j] permet
d’obtenir une nouvelle liste de i à j. On
peut également avoir [i:] et [:j] pour obtenir
la liste depuis i jusqu’à la fin et depuis le debut jusqu’à
j. Finalement, [] permet de copier la
liste.
L = list(range(5))
print(L, id(L))[0, 1, 2, 3, 4] 139955346121920K = L[2:4]
print(K, id(K))[2, 3] 139955346114944T = L[1:]
print(T, id(T))[1, 2, 3, 4] 139955346119104U = L[:-1]
print(U, id(U))[0, 1, 2, 3] 139955347722816Ceci a de grosse conséquence quand on réalise des implémentations récursive sur les listes.
Par exemple, pour calculer la moyenne:
def moyenne_rec(L):
n = len(L)
if n == 1:
return L[0]
return (L[0] + moyenne_rec(L[1:])*(n-1))/nCette fonction à l’air linéaire mais en fait
L[1:] est une opération linéaire ce qui donne une
complexité quadratique.
On peut modifier ça en passant par une fonction auxiliaire avec une variable pointant sur la position courante.
def moyenne_rec2(L):
def _aux(L, i):
if i == 1:
return L[0]
return L[i] + moyenne(L, i - 1)
return _aux(L, len(L) - 1)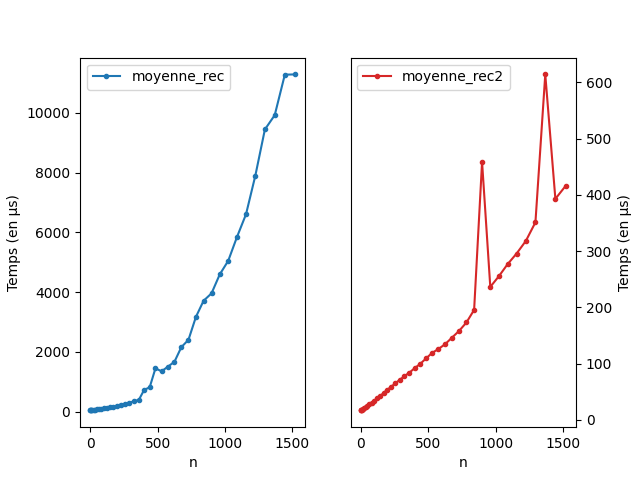
Compiled the: mar. 17 déc. 2024 14:03:16 CET